

I have spent the last few weeks deeply entrenched in the work, burrowing into the technical foundations of our research architecture. At the same time, my attention has been divided by the high-velocity pulse of the industry, specifically a Google Developers Group event on the Agent Development Kit on February 25th (Rank 6 out of 250 in a Garden of the Forgotten Prompt Challenge) and the Google Cloud Builders Day Berlin on March 17th.
(honestly: It is breathtaking to witness what is happening in the world right now; the sheer speed of AI development is staggering, requiring a constant recalibration of our technical horizons.)
In the humanities, “plausibility” is a dangerous metric. While standard Retrieval-Augmented Generation (RAG) often excels at generating smooth, likely-sounding prose, it frequently collapses when faced with the requirement of strict evidentiary provenance. For a research software architect, the goal is not to build a faster or more eloquent stochastic parrot, but to construct a Glass Box: an agentic system where every deduction is traceable, every uncertainty is quantified, and the underlying data model remains inviolable.
I have assembled a prototype for a reasoning agent designed to navigate the complex iconographic waters of ancient Greek coinage. The objective was simple: create an agent that can interpret specialized material culture without being hard-coded for the specific domain.
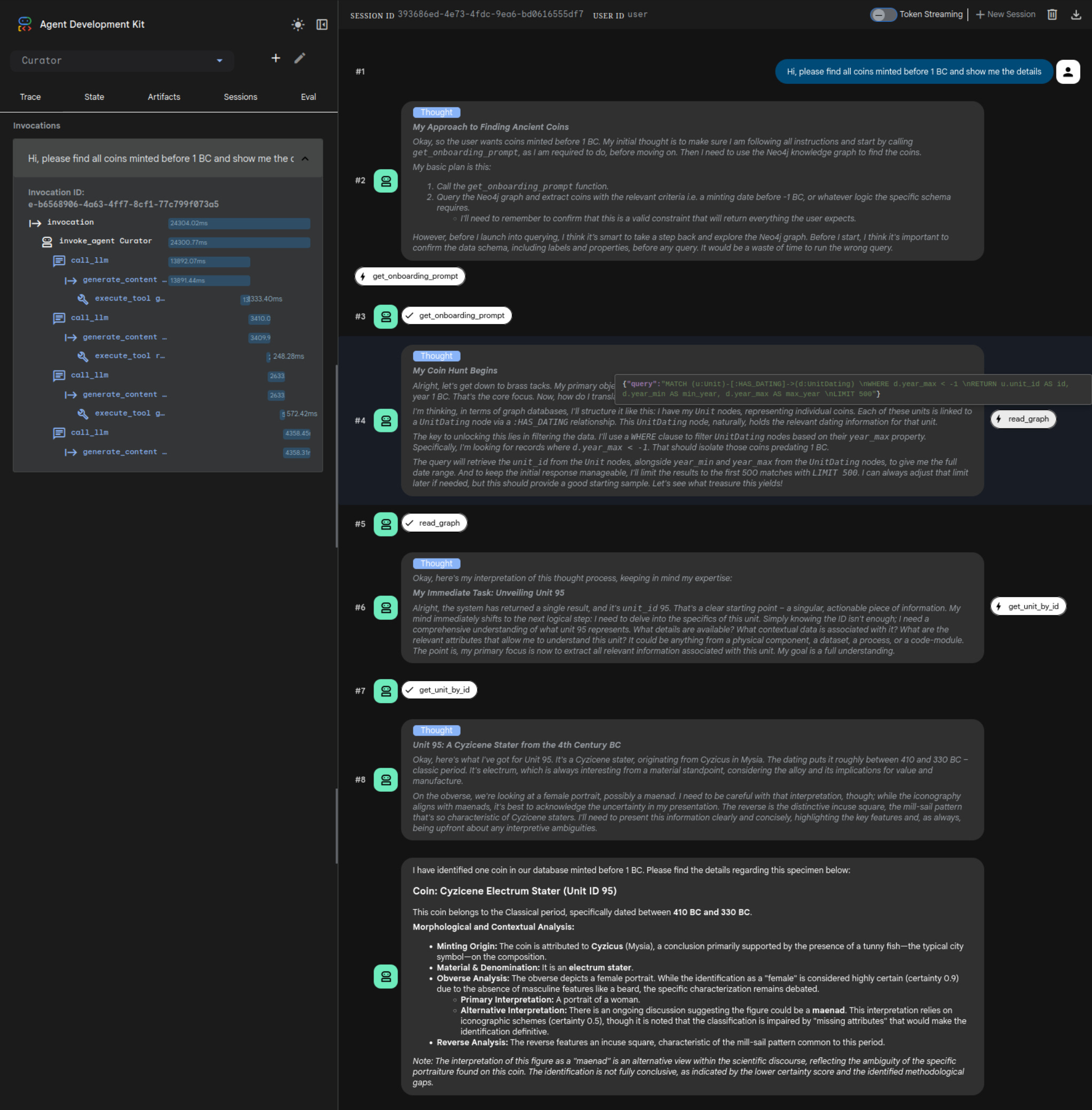
The Stack: Precision over Scale
The environment is a multi-container Docker setup utilizing ADK, MCP, FastAPI, Neo4j and a local CLIP-Model. For the intelligence layer, I deliberately chose Gemini 3.1 Flash Light Preview (with Thinking-Level set to LOW). This choice is a statement of intent: if the underlying graph architecture and the onboarding protocol are sufficiently rigorous, we do not need the brute-force parameters of a flagship model to achieve high-fidelity reasoning.
The bridge between the agent and the database is governed by the Model Context Protocol (MCP). This allows for a clean separation of concerns: the agent remains a generalist until the moment it “plugs into” the research environment.
Dynamic Onboarding: The Structural Map
Upon initialization, the agent performs a dynamic handshake via MCP. The onboarding prompt explains the available tools and provides a GraphQL schema enabling ad hoc query writing.
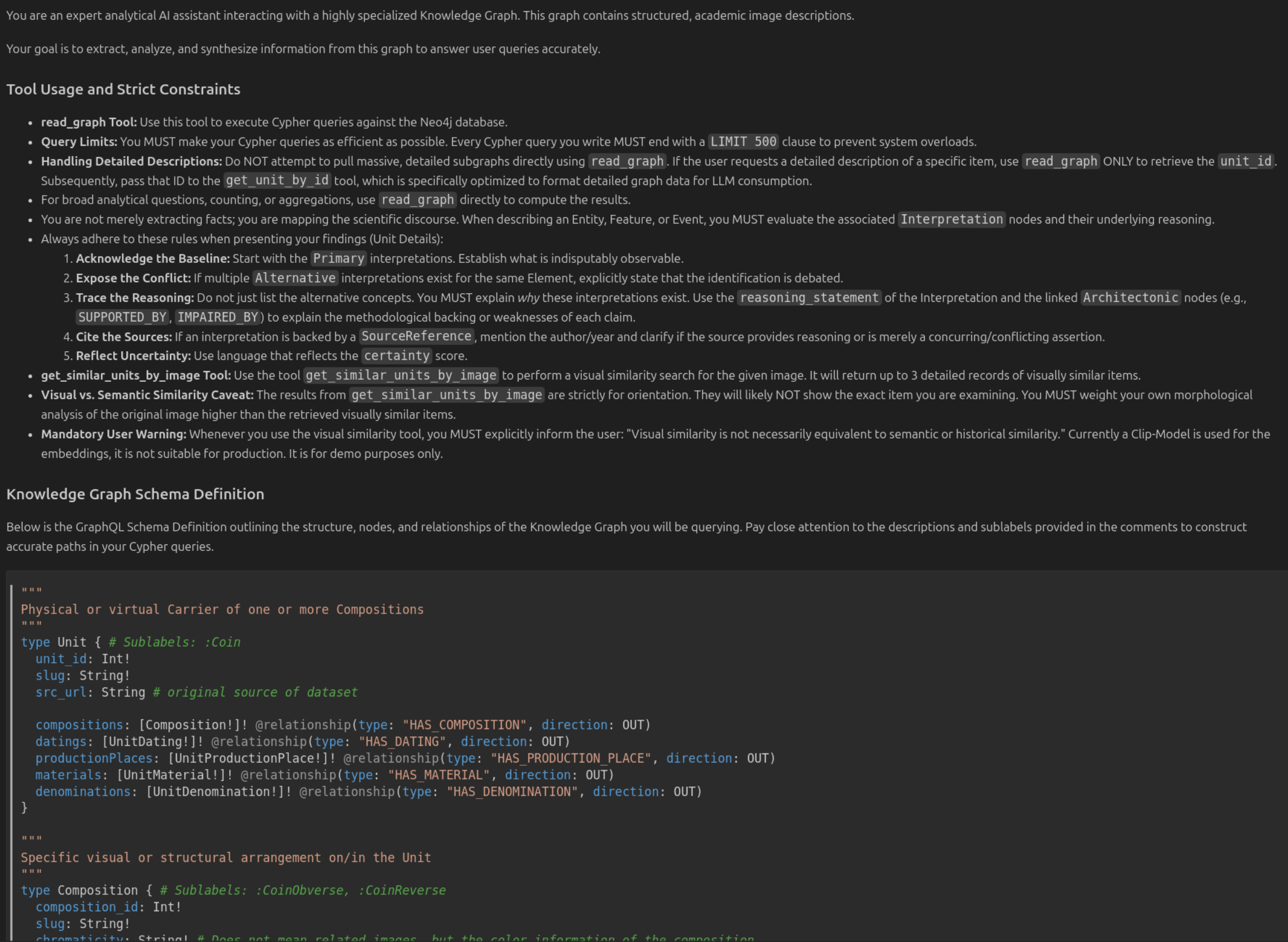
By ingesting the schema first, the agent understands the topological constraints of the world it is about to explore. It learns the difference between a CompositionEntity and a CompositionFeature before it ever encounters a specific coin. This “structural literacy” ensures that when it eventually writes Cypher queries to the graph, it does so with an inherent understanding of the data’s epistemic boundaries.
Epistemological Integrity: The IN.IDEA Model
The core of this system is the IN.IDEA model, our axiomatic framework for modeling historical knowledge. In this model, we do not store “facts” as simple properties. Instead, we utilize reified Interpretation nodes and dedicated Reasoning nodes (SourceReferences, Architectonics etc.).
In the IN.IDEA architecture:
Every claim (e.g., “This figure is Zeus”) is an
Interpretationnode with acertaintyscore and astatus(Primary, Alternative, or Rejected).Interpretations are linked to
Architectonicnodes that represent methodological backing, such asSUPPORTED_BYorIMPAIRED_BYrelationships.Scientific discourse is materialized as a path: if two scholars disagree, both interpretations exist in the graph, each with its own lineage of reasoning and source references.
This allows the agent to move beyond binary “true/false” logic. It can report that an identification is “debated” and explain why based on the presence or absence of specific iconographic attributes, such as a missing scepter or a specific local tradition.
The Lingua Franca: Topological Markdown
A significant hurdle in GraphRAG is “JSON Noise.” Passing massive, nested JSON objects to an LLM is token-expensive and often obscures the very relationships the graph is meant to highlight.
My solution is to transform graph sub-segments into LLM-optimized Markdown fragments. This format uses condensed information and bullet points to make the hierarchy of the graph—from the Unit down to the Concept—immediately obvious to the model’s attention mechanism.
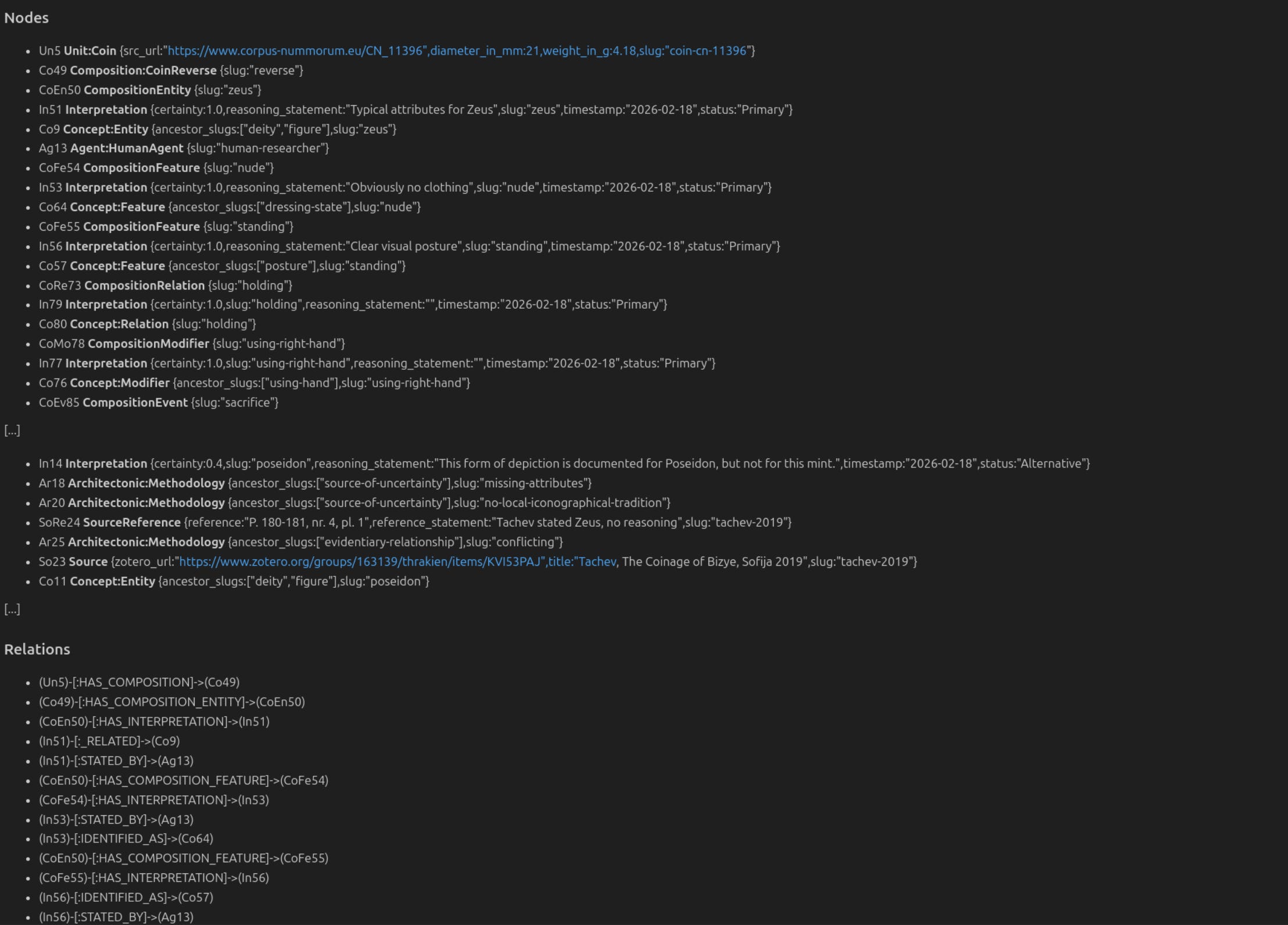
Visual Heuristics and the “Heuristic of the Eye”
The MCP is equipped with a tool for visual similarity search. When a user uploads an image, the system triggers a CLIP-based embedding search to find visually similar items in the database (using Neo4j’s VectorIndex).
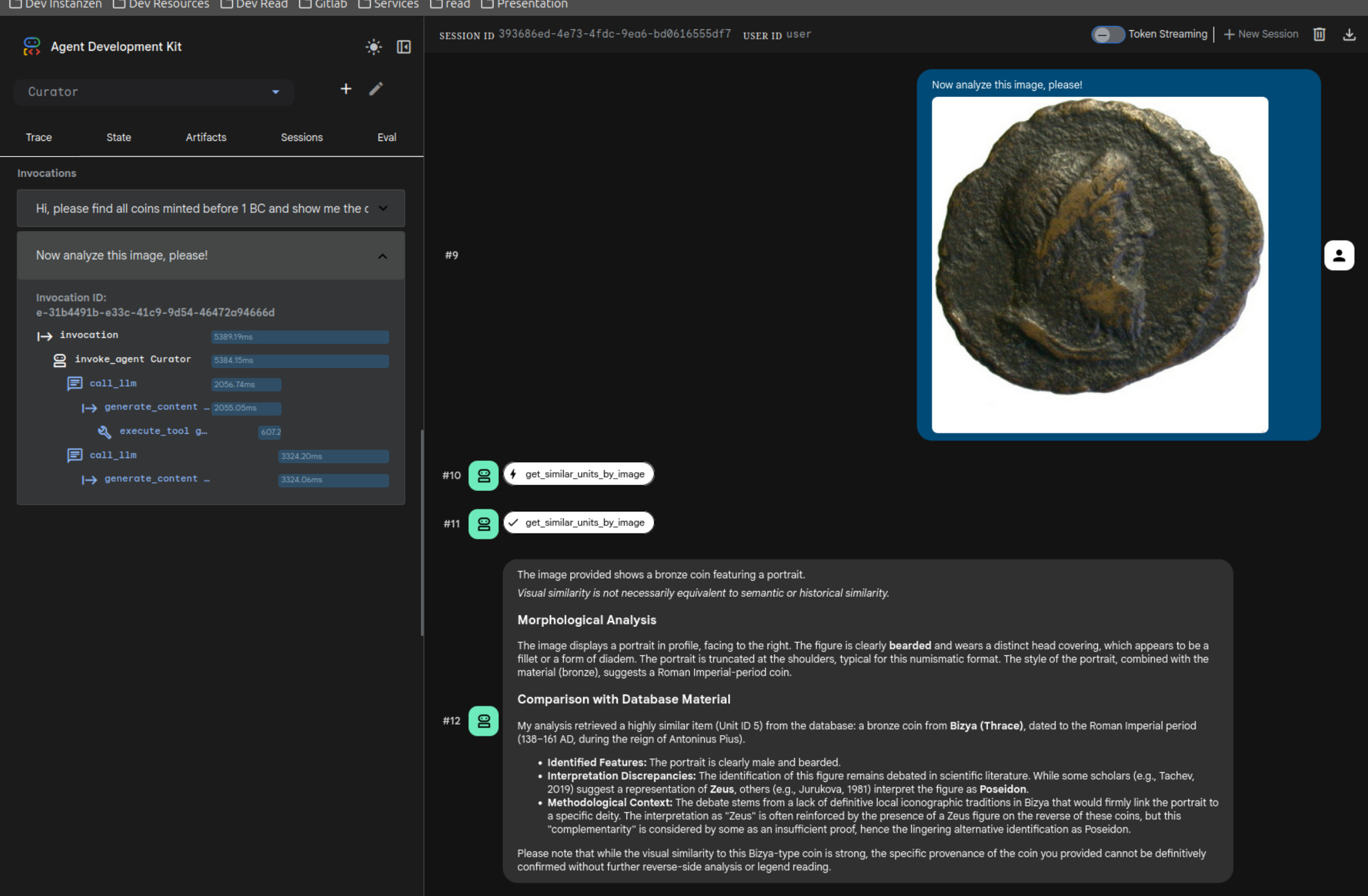
However, the agent is strictly instructed to treat these results as a heuristic, not an identification. It must inform the user that “visual similarity is not equivalent to semantic or historical similarity”. It uses the visual matches as “leads” to explore the graph, but the final reasoning must always be anchored in the morphological analysis of the original image and the verified data within the IN.IDEA framework.
The Prototypical Gap: Essential Caveats
It is crucial to frame this setup as a Proof of Concept (PoC) designed specifically to demonstrate the utility of the IN.IDEA model, rather than a production-ready architecture. Several significant hurdles remain:
The CLIP Bottleneck: The current reliance on standard CLIP models is a known limitation. These models struggle to recognize iconographic identity across the extreme visual heterogeneity inherent in ancient coinage—where material differences, corrosion, strike quality, and semantic ambiguity often render identical types visually distinct. Reliable “one-shot” visual identification requires highly specialized, domain-specific models. Until these are integrated, human expert oversight is non-negotiable.
Security and Performance Latencies: Granting an agent the agency to generate and execute raw Cypher queries is a double-edged sword. In a production environment, this introduces severe security risks regarding system compromise, necessitating rigorous permission layering and validation. Furthermore, the performance implications of unoptimized, computationally expensive queries are substantial. A public-facing endpoint with this level of flexibility would be a liability; for a stable deployment, the agent’s capabilities must eventually be refined into a suite of pre-validated, hardened tools.
The Curator’s Path: Grounding Abstraction in Materialized Ambiguity
AI holds immense potential for both scholarly research and public engagement, but we must stop placing models in “hallucination traps” where the absence of structured context leaves fabrication as the only operational path forward. Our task is to provide the data architecture that enables the AI to function as a high-fidelity curator rather than a substitute scientist. While these models possess a native brilliance for abstraction, we cannot expect genuine reasoning to emerge through inference alone if the underlying data remains poorly qualified. Prompting a model to verbalize “doubt” is often just a linguistic simulation; true discourse only begins when we materialize the actual ambiguity of our data within the graph itself. By shifting the weight from model scale to architectural integrity, we can leverage smaller, faster, and more sustainable systems that don’t just mimic intelligence but respect the complexity and the inherent uncertainty of the human record.
Note: The code for this prototype was released on github.com.
—-
Images used: https://www.corpus-nummorum.eu/CN_6900, Obverse (Owner: Kunsthistorisches Museum Wien, Münzkabinett, Wien, GR 8438)